- 4.1 引言
- 一个基本的MIPS实现
- 我们将要设计的实现方式包含了MIPS指令集的一个核心子集:
- 存储器访问指令:取字(lw)和存字(sw)
- 算术逻辑指令:加法(add)、减法(sub)、与运算(AND)、或运算(OR)和小于则设置(slt)
- 分支指令:相等则分支(beq)和跳转(j)
- 我们将要设计的实现方式包含了MIPS指令集的一个核心子集:
- 实现方式概述
- 实现每种指令的前两步是一样的
- 程序计步器(PC)指向指令所在的存储单元,并从中取出指令。
- 通过指令字段内容,选择读取一个或两个寄存器。对于取字指令,只需读取一个寄存器,而其他大多数指令要求读两个寄存器
- 这两步之后,为完成指令而进行的步骤则取决于具体的指令类型。
- 但是对于三种类型指令的每一种而言,其动作大致相同,与具体指令无关
- 例如,在除了跳转指令之外的所有指令在读取寄存器后,都要使用算术逻辑单元(ALU)。
- 存储器使用ALU计算地址,算术逻辑指令用ALU执行运算,分支指令用ALU进行比较。
- 在使用ALU之后,完成不同指令所需的动作就有所不同了。
- 存储访问指令需要访问内存以便读取和存储数据。
- 算术逻辑指令或取数指令将来自ALU或存储器的数据写入寄存器。
- 分支指令则需要根据比较的结果决定是否改变下一条地址:如果不修改下一条地址,则下一条指令地址默认是当前指令地址+4

- 某个单元的数据可能来自两个不同的单元
- 所以不能简单地直接将这些数据线连在一起,必须增加一个逻辑单元用以从不同的数据来源中选择一个送给目标单元。
- 这个过程通常是由一个叫多选器的逻辑单元完成的
- 图中还有一个控制单元
- 它以输入为指令,决定功能单元和两个多选器的控制信号。
- 第三个多选器是用来决定是将PC+4还是分支目的写入PC
- 实现每种指令的前两步是一样的
- 一个基本的MIPS实现
- 4.2 逻辑设计的一般方法
- 组合单元:一个操作单元,如门或ALU
- 状态单元:一个存储单元,如寄存器或存储器
- 一个状态单元至少要有两个输入(写入单元的数据值和何时写入的时钟信号)和一个输出(提供前一个时钟信号写入单元的数据值)
- 时钟方法规定了信号可以读入和写入的时间
- 控制信号:用来决定多选器选择或指示功能单元操作的信号;它与数据信号相对应,数据信号包含由功能单元操作的信息
- 有效:信号为逻辑高或真
- 无效:信号为逻辑低或假
- 4.3 建立数据通路
- 数据通路部件:一个用来操作或保存处理器中数据的单元。在MIPS实现中,数据通路部件包括指令存储器、数据存储器、寄存器堆、ALU和加法器
- 程序计步器:存放下一条将要被执行指令的地址的寄存器
- !!!!!!!!!!!!!!!!!!!!!!!!!!
- 这部分记得补全并仔细琢磨
- 4.4 一个简单的实现机制
- 我们用上面的数据通路和增加一个简单的控制单元来实现一个MIPS体系结构。
- 这一结构实现了取字、存字、相等则分支和算术逻辑指令加法、减法、与运算、或运算和小于则置位(set on Less Than),后面我们还将实现跳转指令
- 4.4.1 ALU控制
- 0000 与
- 0001 或
- 0010 加
- 0110 减
- 0111 小于则置位
- 1100 或非
- 根据指令类型的不同,ALU将上述5种功能中的一种(除了或非)
- 根据低6位的funct字段,ALU执行5种操作种的一种。对相等则分支指令,由ALU执行减法操作
- 使用一个小的控制单元即可生成4位的ALU控制信号,其输入为funct字段和2位的ALUOp字段。
- ALUOp字段指明要进行的操作是存取指令需要的加法(00)、还是beq需要的减法(01),由指令的funct字段(10)决定。该ALU控制单元输出4位信号,即4位控制信号,直接对ALU进行控制。
- 多级译码(主控制单元生成ALUOp作为ALU控制单元的输入,再由ALU控制单元生成真正的控制ALU的信号)的方法是一种常用的实现方式,可以减小主控制单元的规模,使用多个小控制单元还可能提高控制单元的速度。而控制单元的性能对时钟周期非常关键
- 4.4.2 主控单元的设计
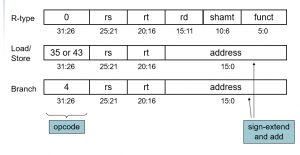
- 三种指令类型的格式:R型指令、分支指令和存取指令
- R型指令:
- 操作码为0,寄存器操作数有三个rs、rt和rd
- rs和rt作为源操作数,rd字段为目的操作数
- funct字段指出ALU功能,由前面设计的ALU控制单元译码
- 我们实现的R型指令有 add sub AND OR和slt(这个是啥来着??)
- shamt字段只用于移位指令
- 取数指令(35_10)和存储指令(操作码=43_10):
- rs寄存器作为基址与16位的地址字段相加以得到访存地址
- rt
- 对取数指令,rt是取出数据的目的寄存器
- 对存储指令,rt是要写入存储器的数据所在的其存钱
- 相等则分支指令(操作码=4):
- rs和rt是源寄存器,用于比较是否相等
- 16位地址进行符号扩展、移位后与PC+4相加以得到分支目标地址
- MIPS的指令格式遵循以下规则:
- Op字段,亦称操作码,总是以31:26位。我们用Op[5:0]来表示
- 对于R型指令、分支指令和存取指令,要读取的两个寄存器为rs和rt字段,分别为25:21位和20:16位
- 存取指令的基址寄存器在25:21位中(rs字段)
- 相等则分支指令、存取指令的16位偏移量在15:0位中
- 有两个地方存放目标寄存器。
- 对取数指令为20:16字段(rt)
- 对R型指令为15:11字段(rd)。
- 所以我们需要一个多选器,以指示要写的寄存器号在哪个字段中
- 操作码:指示指令操作和格式的字段
- 数据通路的操作
- R型指令
- eg:add $t1,$t2,$t3
- 分四步
- 从指令存储器中取出指令,PC自增
- 从寄存器堆中读出寄存器$t1和$t2。同时,主控制单元计算出各控制信号的状态
- ALU根据funct字段(指令的5:0位)确定ALU的功能,对从寄存器堆读出的数据进行操作
- 将ALU的结果写入寄存器,根据指令的15:11位选择目标寄存器($t1)
- 取数指令
- eg:lw $t1, offset($t2)
- 分五步
- 从指令存储器中取出指令,PC自增
- 从寄存器堆中读出寄存器$t2的值
- ALU将从寄存器读出的值与符号扩展后的指令低16位(offset)相加
- 将ALU的结果作为数据存储器的地址
- 存储单元的数据写入寄存器堆,目标寄存器由指令的20:16位($t1)指出
- 相等则分支指令
- eg:beq $t1、$t2、offset
- 分四步
- 从指令存储器中取出指令,PC自增
- 从寄存器中取出寄存器$t1和$t2的值
- ALU将从寄存器堆读出的两数相减。PC+4的值与符号扩展并左移两位后的指令低16位(offset)相加,结果即分支目标地址
- 根据ALU的零输出决定到哪个加法器的结果存入PC中
- 控制的结束
- 单周期实现:也被称为单时钟周期实现,即一个时钟周期执行一条指令的实现机制。
- 4.4.3 为什么不用单周期实现方式
- 无法胜任包含浮点数或更复杂指令
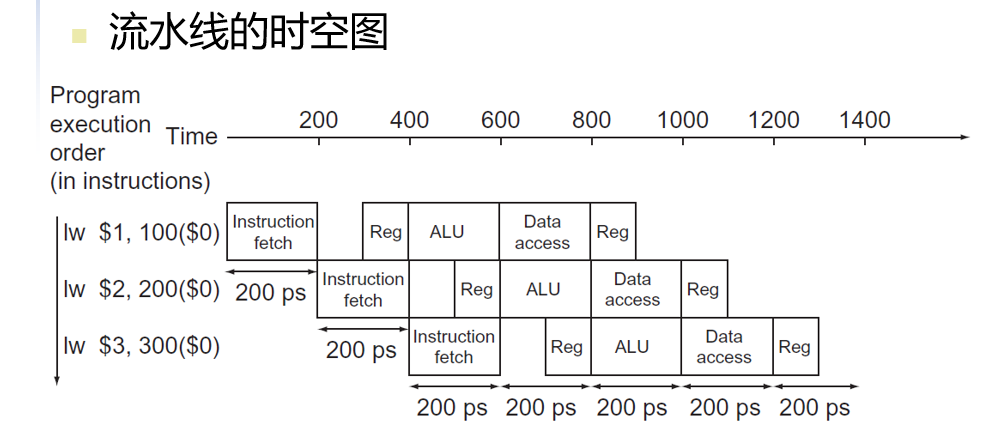
- 4.5 流水线概述
- 流水线:一种实现多条指令重叠执行的技术
- 通常,一个MIPS指令包含如下五个处理步骤:
- IF:从指令寄存器中读取指令
- ID:指令译码的同时读取寄存器。(MIPS的格式允许同时进行指令译码和读取寄存器)
- EX:执行操作或计算地址
- MEM:从数据存储器中读取操作数
- WB:将结果写回寄存器
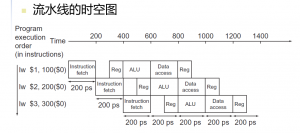
- 计算机流水线的处理时间也受限于最慢的处理步骤,即ALU操作和存储器访问
- 同时我们假设堆寄存器堆的写操作发生在时钟周期的前半段,对寄存器堆的读操作发生在时钟周期的后半段
- 所有的流水级都只花费一个周期的时间,所以,时钟周期必须能够满足最慢操作的执行需要
- 如果各阶段操作平衡,那么在流水线机器上的指令执行时间为
- 指令执行时间_流水线 = 指令执行时间_非流水线 / 流水线级数
- 4.5.1 面向流水线的指令集设计
- 所有MIPS指令的长度都是相同的
- MIPS只有很少的几种指令格式
- MIPS中的存储器操作数仅出现在存取指令中
- 所有操作数必须在存储器中对齐
- 4.5.2 流水线冒险
- 结构冒险:因缺乏硬件支持而导致指令不能在预定的时钟周期内执行的情况
- eg:第一条指令在访问存储器的同时,第四条指令将会在统一存储器中预取指令
- 数据冒险:因无法提供指令执行所需数据而导致指令不能在预定的时钟周期内执行的情况
- eg:在紧跟的减法指令需要用到前面加法指令的结果时,因在加法的具体实现过程中,需要第五步才能返回和,所以会严重阻碍流水线
- add $s0,$t0,$t1
- sub $t2,$s0,$t3
- 可以通过编译器来解决这种数据冒险的发生,但实际上这种冒险的发生过于频繁而且导致的延迟时间太长
- 一种最基本的解决方法是基于以下发现的:在解决数据冒险问题之间不需要等待指令的执行结束
- 对于以上例子,一旦ALU生成了加法运算的结果,就可以将它用作减法运算的一个输入项。
- 前推:也称旁路。一种解决数据冒险的方法,具体做法是从内部寄存器而非程序员可见的寄存器或存储器种提前取出数据
- 取数—使用型数据冒险:一类特殊的数据冒险,指当装载指令要取的数还没取回来时其他指令就需要使用的情况
- 此时我们不得不阻塞一个程序
- 流水线阻塞:也被称为气泡。为了解决冒险而实施的一种阻塞
- 控制冒险:也称分支冒险。因为取到的指令并不是所需要的(或者说指令地址的变化并不是流水线所预期的)而导致指令不能在预定的时钟周期内执行
- eg:决策以来于一条指令的结果,而其他指令正在执行中
- 有两种办法可以解决控制:
- 一是阻塞:在未取到所需指令之前串行
- 二是预测:
- 预测正确时,流水线全速运行,当分支发生时,流水线才会发生阻塞
- 一种更加成熟的方法是预测一些分支发生而一些不发生
- 分支预测:一种解决分支冒险的方法。它预测分支结果并立即沿预测方向执行,而不是等真正的分支结果确定后才开始执行
- 静态分支预测:
- 由编译器执行
- 基于典型的分支行为
- 动态分支预测:
- 硬件度量实际分支行为,
- 记录每个分支机构的近期历史
- 假设未来的行为将继续趋势
- 如果出错, 请在重新提取时停止, 并更新历史记录
- 硬件度量实际分支行为,
- 较长的流水线会恶化预测的性能,并会提高错误预测的代价
- 结构冒险:因缺乏硬件支持而导致指令不能在预定的时钟周期内执行的情况
- 4.5.3 对流水线概述的小结
- 流水线增加了同时执行的指令数目以及指令开始和结束的速率。
- 流水线并不能够减少单一指令的执行时间,也称为延迟。
- 例如,一个五级流水线仍然需要5个时钟周期来完成一条指令。
- 流水线提供了指令的吞吐率而不是减少了单条指令的执行时间或延迟
- 4.6 流水线数据通路及其控制
- 又臭又长 暂略
- 4.7 数据冒险:旁路与阻塞
- 暂略!!!
- 空指令:一种不进行任何操作或不改变任何状态的指令
- 4.8 控制冒险
- 4.8.1 假定分支不发生
- 一种比较普遍的提高速度的方法是假设分支不发生,并继续执行顺序的指令流。
- 如果分支已经发生,就丢弃已经读取并译码的指令,并按分支目标继续执行
- 清除:因发生了意外而丢弃流水线中的指令
- 4.8.2 缩短分支的延迟
- 确定目标地址的时间越早越好。
- 为了将分支决策提前,需要提前两个动作:计算分支目标地址和判断分支条件
- 4.8.3 动态分支预测
- 静态分支预测:
- 由编译器执行
- 基于典型的分支行为
- 动态分支预测:根据运行信息在运行中进行分支预测
- 硬件度量实际分支行为,
- 记录每个分支机构的近期历史
- 假设未来的行为将继续趋势
- 如果出错, 请在重新提取时停止, 并更新历史记录
- 硬件度量实际分支行为,
- 静态分支预测:
- 4.8.1 假定分支不发生
- 4.9 异常
- 异常:也称中断,指打断程序正常执行的突发事件,用于检测溢出等
- 中断:来自处理器外部的异常
- 暂略
- 4.10 指令集并行
- 指令级并行:之零件的并行性
- 多发射:一种单时钟周期内发射多条指令的机制
- 一个多发射处理器主要有两种形式:
- (编译时)静态多发射
- (执行时)动态多发射
- 多发射流水线必须处理以下两个问题:
- 往发射槽中发射多条指令
- 处理数据冒险和控制冒险
- 4.10.1 推测的概念
- 推测:一种编译器或处理器推测指令结果以消除执行其他指令对该结果依赖的方法
- 推测的问题在于可能会猜错,所以任何推测技术必须包含回卷能力,实现这种能力增加了额外的复杂性
- 4.10.2 静态多发射处理器
- 静态多发射处理器都使用编译器来帮助封装多条指令并处理冒险。
- 在一个静态发射处理器中,可以在给定时钟周期内发射多条指令,也成为发射包
- 因为静态多发射处理器一般对一个时钟内能发射的多条指令有所限制,因此把发射包堪称允许同时进行很多操作的一条指令是可行的。这种观点引出了这种方法最初的名字:超长指令集。
- 循环展开:一种从存取数组的循环中获取更多性能的技术,其中循环体会被复制多分并且与32位内存边界对齐
- 寄存器重命名:
- 由编译器或硬件对寄存器进行重命名以消除反相关
- 反相关:也被称为名字相关,因为寄存器名的重用导致的相关,并非由两条指令中使用同一个值导致的真正相关
- 4.10.3 动态多发射处理器
- 超标量:一种高级流水线技术,可以使每个周期处理器能执行的指令数超过一条
- 动态流水线调度:对指令进行重排序以避免阻塞的硬件支持
- 在这种处理器中流水线被分为3个主要单元:
- 取值与发射单元、多个功能单元和一个提交单元
- 提交单元:位于动态流水线和乱序流水线中的一个单元,用以决定合适可以安全地将操作结果送至程序员可见的寄存器和存储器
- 取值与发射单元、多个功能单元和一个提交单元
- 重排序缓存区:
- 动态调度处理器中用于暂时保存执行结果的缓存区,等到安全时才将其中的结果写回寄存器或存储器
- 在这种处理器中流水线被分为3个主要单元:
- 暂略
- 4.10.4 能耗效率与高级流水线
- 暂略
- 4.11 实例:ARM Cortex-A8 和 Intel Core i7 流水线
- 暂略
- 4.12 运行更快:指令集并行和矩阵乘法
- 暂略
- 4.13 高级主题:通过硬件实际语言描述和建模流水线来介绍数字设计以及更多流水线实例
- 暂略
- 4.14 谬误与陷阱
- 谬误:流水线是一种简单的结构
- 谬给:流水线概念的实现与工艺无关
- 陷阱:没用考虑指令集的设计反过来会影响流水线
- 4.15 本章小结
- 指令延迟:执行一条指令真正所花的时间