- 5.1 引言
- 存储器层次结构:一种由多存储器层次组成的结构,存储器的容量和访问时间随着离处理器的距离增加而增加
- 局部性原理:
- 时间局部性:某个数据项在被访问之后可能被再次访问的特性
- 空间局部性:某个数据项在被访问之后,与其相近的数据项可能很快被访问的特性
- 存储器层次结构可以由多层组成,但数据只能在相邻的两个层次之间进行复制,因此我们将注意力重点集中在两个层次上
- 高层的存储器靠近处理器,比底层存储器容量小但访问速度更快
- 我们将一个两级乘此结构中存储信息交换的最小单元称为块或行
- 如果处理器需要的数据存放在高层存储器中的某个块中,则称为一次命中
- 如果没用找到,则称为一次缺失,随后访问底层存储器来寻找所需数据的那一块
- 块或行
- 可存在于或不存在于cache中的信息的最小单元
- 命中率
- 在高层存储器中找到目标数据访问比例
- 缺失率
- 在高层存储器中没用找到目标数据的存储访问比例
- 命中时间
- 访问某存储器层次结构所需要的时间,包括了判断当前访问是命中还是缺失的时间
- 缺失代价
- 将相应的块从底层存储器替换到高层存储器所需的时间,包括访问块、将数据逐层传输、将数据插入发生缺失的层和将信心块传递给请求者的时间
- 5.2 存储器技术
- 目前,构建存储器层次结构主要有4种技术。
- 第一种,主储存器由DRAM(动态随机存取存储器)实现
- 第二种,靠近处理器的那层(cache)则由SRAM(静态随机存取存储器)实现
- DRAM每比特占用的存储器空间较少,等量的硅制造的DRAM的容量比SRAM要大
- DRAM每比特成本要低于SRAM,但是速度比SRAM慢
- 第三种,闪存,这种非易失性存储器用作个人移动设备种的二级存储器
- 第四种,磁盘,通常是服务器中容量最大且速度最慢的一层
- 从第一种到第四种,典型访问时间递增,价格递减
- 5.2.1 SRAM技术
- SRAM是一种组织成存储阵列结构的简单集成电路,通常具有一个读写端口
- 虽然读写的hi见可能不同,但SRAM对任何数据访问时间都是固定的
- SRAM不需要刷新,并且其访问时间与周期时间非常接近
- 为了防止读操作时信息丢失,SRAM的一个基本存储单元通常由6~8个晶体管组成
- 在空闲模式下,SRAM只需要最小的功率来保持电荷
- 5.2.2 DRAM技术
- 在DRAM中,存储单元使用电容保存电荷的方式来存储数据
- 为了保存的电荷进行读取或写入,使用一个晶体管对该电容进行访问
- 因为DRAM每一位都只使用一个晶体管,所以它比SRAM密度要高得多,价格也便宜得多
- DRAM在电容上保存电荷,因此不能长久地保持数据,从而必须周期性地刷新(所以动态)
- 为了对单元进行刷新,只需要读出其内容然后写回即可
- 为了进一步优化与处理器的接口,DRAM增加了时钟,因此称之为同步DRAM,简写为SDRAM
- SDRAM的优势在于使用时钟对存储器和处理器保持同步,其速度上的优势主要源于不需要额外指定地址位以突发方式传送多个数据的能力
- 最鲁埃的版本为双数据速率(DDR)SDRAM
- 该名称表示在时钟的上升沿和下降沿都要传送数据,因此可以获得双倍的数据带宽
- 该技术的最新版本是DDR4
- 5.2.3 闪存
- 闪存是一种电可擦除的可编程只读存储器(EFPROM)
- 与磁盘和DRAM不同,对闪存的写操作可以使存储位损耗
- 为了应对限制,大多数闪存产品都有一个控制器,用来将写操作已经写入很多次的块中映射到写入次数较少的块中
- 这种技术称为损耗均衡(wear leveling)
- 5.2.4 磁盘存储器
- 一个磁质硬盘包含一组圆形磁盘片,它们绕着轴心每分钟转动5400~15000周
- 为了对磁盘上的信息进行读写,每层的表面有一个包含小的电磁线圈的读写磁头
- 整个驱动器被永久地密封起来以控制驱动器中的环境,从而使得磁头可以距离驱动器表面非常近
- 每个磁盘的表面划分为同心圆盘,称为磁道(track)
- 磁道:位于磁盘表面的数万个同心圆环中的任意一个圆环称为一个磁道
- 每个面通常有几万条磁道,每条磁道同样被划分为用于存储信息的扇区
- 扇区:构成磁盘上磁道的基本单位,是磁盘上数据读写的最小单位
- 柱面:磁头在给定时访问到所有盘面上的所有扇区的集合
- 寻道:把读写磁头移动到磁盘上适当的磁道上面的过程
- 旋转延时:
- 在磁头定位后,指定扇区通过读写头的所需时间,通常是磁盘转动一周时间的一半
- 顺序的块可能在不同的磁道上
- 概括起来,磁盘和半导体存储器技术的主要差别是磁盘的访问速度慢,这主要是因为它们是机械器件
- 闪存比磁盘快1000倍,DRAM比磁盘快100000倍??理论上吧??
- 磁盘与闪存一样,是非易失的,但它不存在写损耗问题
- 但闪存更加坚固,因此适用于个人移动设备
- 动态随机存取存储器 (DRAM)
- 主内存
- 静态随机存取存储器 (SRAM)
- 缓存和寄存器
- 昂贵和更快
- 闪存
- USB 闪存盘, 固态硬盘
- 磁
- 硬盘
- 5.3 cache的基本原理
- cache:高速缓冲存储器
- 早期:cache是处理器与主存之间的特殊层次
- 现在,也指代基于局部性原理来管理的存储器
- 如今构建的每台通用计算机, 从服务器到低功耗嵌入式处理器, 都包括缓存
- 直接映射:一种cache结构,其中每个存储器地址仅仅对应到cache中的一个位置
- 几乎所有的直接映射都使用以下的映射方式:
- (块地址) mod (cache中的块数)
- 几乎所有的直接映射都使用以下的映射方式:
- 所以cache中的每个位置可能对应于主存中多个不同的地址
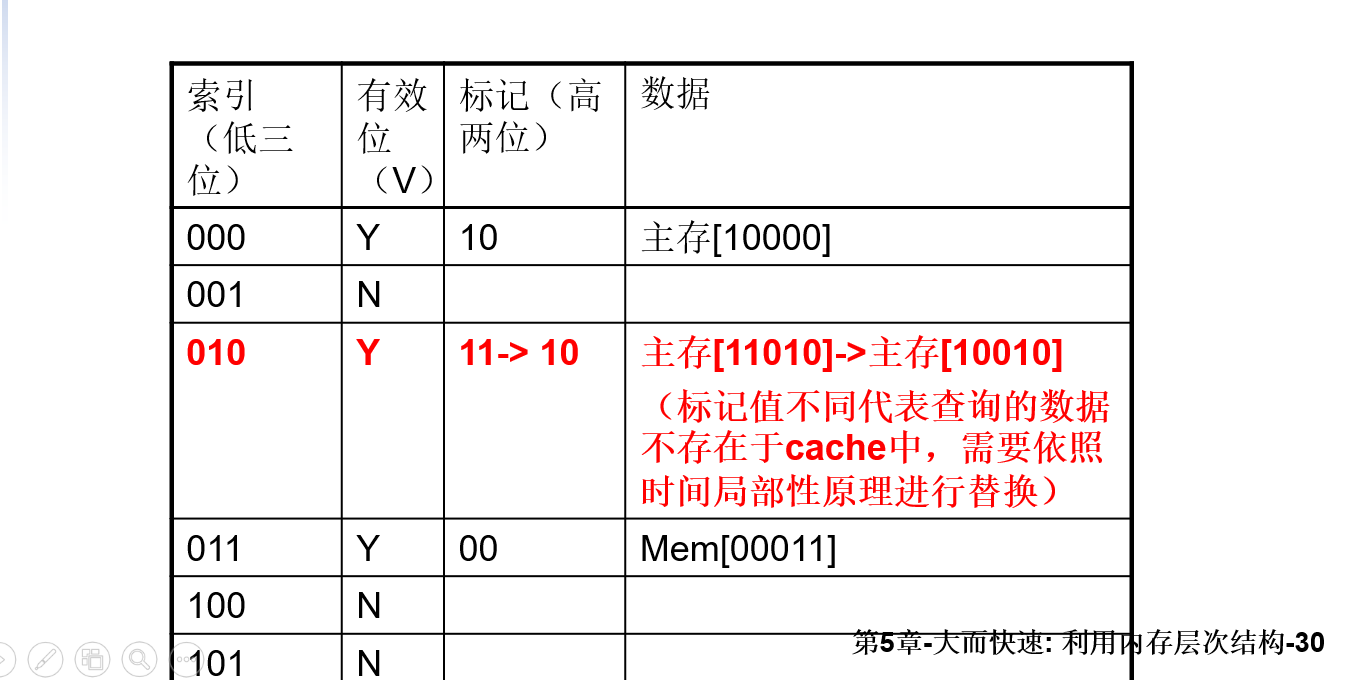
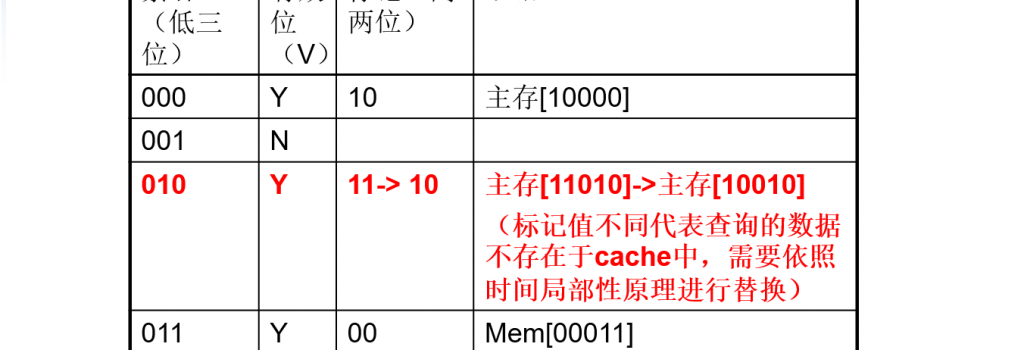
- 如何知道请求的字是否在cache中?
- 我们可以在cache中增加一个标记
- 标记:表中的一个字段,包含了地址信息,这些地址信息可以用来判断cache中的字是否就是所请求的字
- 标记只需包含地址的高位,也就是没用用来检索cache的那些位
- 加入地址有5位,那么标记位只需使用高两位,而低三位的索引域则用来选择cache中的块
- 如何判断cache块中没用包含有效信息(空)?
- 最常用的方法就是增加一个有效位来标识一个块是否含有一个有效地址
- 有效位:表中的一个字段,用来表示一个块是否含有一个有效数据
- cache可能是预测技术中重要的例子。它依赖于局部性原理尽可能在存储器层次结构的更高一层寻找需要的数据,并且预测错误时能够从存储器低一层中寻找需要的正确数据的机制。
- 现代计算机中cache预测命中的概率通常高于95%
- 5.3.1 cache访问
- 访问具有内存地址的缓存
- 读取由索引值指定的条目
- 与标记值进行比较
- 检查有效的位
- 如果标记和有效位处于打开,然后请求在缓存中命中,数据被提供给处理器
- 否则, 将发生缺失
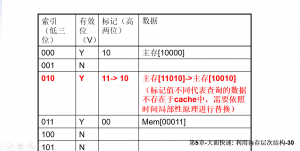
- 匹配到索引而标记不匹配时,依据时间局部性原理进行数据以及标记位的更新
- 在直接映射中,只有一个位置可以存放最新请求的数据项,因此对于哪个数据项被替换也只有一种选择
- 对于每个可能的地址,在cache中进行如下查找:
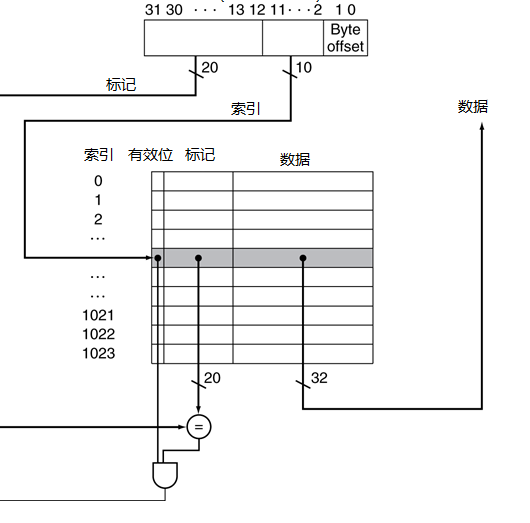
- 地址的低位用来找到chche中与该地址匹配的唯一项
- 上图说明一个地址可以划分为
- 标记域:用来与cache中标记域的值进行比较
- cache索引:用来选择快
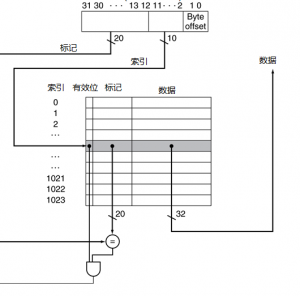
- 对于这个cache,地址的低位用来选择由数据字和标记组成的一个cache项
- 这个cache中有1024个字,即4KiB
- 我们假设使用32位的地址
- cache中的标记与地址高位相比较,判断cache中的项是否符合请求的地址
- 由于cache有1024个子,块大小为1一个字,因此,缩影需要10位,剩下的32-10-2=20位用来和标记相比较
- 如果和地址的高二十位相等,并且有效位开启,那么请求在cache中命中,相应的字被提供给处理器,否则,发生缺失
- cache的索引以及标记唯一确定了cache块中存放内容的主存地址
- 由于索引域用来寻址,而一个n位的域有2^n种值,直接映射cache种项的总数必须为2的幂
- 在MIPS体系中,由于字是以4字节的倍数对齐的,每个地址至少有两位用来指定字种的一个字节,因此选择块种的一个字时至少两位被忽略
- 由于cache不仅存储数据也存储标记位,cache所需的总位数是cache大小和地址的函数。在前面提到的块的大小为1个字,但通常块大小为多字,就像下面的情况:
- 32位地址
- 直接映射cache
- cache大小为2^n个块,因此n位用来被索引
- 块大小为2^m个字(2^(m+2)字节),因此m位用来查找块中的字,两位是偏移信息。
- 标记域的大小为:32-(n+m+2)
- 直接映射的cache的总位数为:2^n x (块大小+标记域大小+有效位域大小)
- 由于块大小为2^m个字(2^(m+5)位),同时我们需要一位有效位,因此这样一个cache的位数是
- 2^n *(2^m * 32 +31 – n – m)
- 访问具有内存地址的缓存
- 5.3.2 缺失处理
- cache缺失:由于数据不在cache中而导致被请求的数据不能满足
- cache中缺失的处理步骤:
- 把程序计步器(PC)的原始值(当前PC-4)送到存储器中
- 通知主存执行一次读操作,并等待主存访问完成
- 写cache项,将从主存取回的数据写入cache中存放数据的部分,并将地址的高位(从ALU中得到)写入标记域,设置有效位
- 重启指令执行第一步,重新取指,这次该指令在cache中
- 数据访问时对cache的控制基本相同:
- 发生缺失时,处理器发生阻塞,直到从存储器中取出数据后才响应
- 5.3.3 写操作处理
- 如果有一个store指令,我们只将数据写入cache(从而不改变主存的内容);那么在写入cache之后,主存与cache相应位置的值将不同,这种情况下,cache和主存被认为不一致
- 保持主存和cache一致性最简单的方法就是将这个数据同时写入主存和cache中,这种方法称为写直达(write-through)法
- 写直达:也译为写通过或写穿。写操作总是同时更新cache和下一存储器层次,以保持二者一致性
- 写操作要考虑的另一个主要方面就是写缺失的情况。
- 我们首先从主存中取出块的字
- 数据块被取回并存入cache中后,将引起缺失的字重新写入cache中,同时,我们使用全地址将该字写入主存
- 但是以上方案无法提供良好的性能,每次写入都会导致数据写入主内存,导致访问内存的速度比访问缓存慢10倍
- 如何解决写直达方案中的性能问题?
- 方案:写缓冲区在等待写入内存时存储数据
- CPU 将数据写入缓存和写入缓冲区, 然后继续执行程序
- 写入缓冲区将数据写入内存
- 当对主内存的写入完成时, 写入缓冲区中的条目将被释放
- 写缓冲区的适当大小是多少?
- 性能和成本之间的权衡
- 写缓冲:一个保存等待写入主存数据的缓冲队列
- 替代写直达的方案是写回:
- 写回:当发生写操作时,新值仅仅被写入cache块中,只有当修改过的块被替换时才写到较低层存储结构中
- 很多写回机制的cache也使用写缓冲,当在发生缺失替换一个被修改的的块时,写缓冲可以起到降低缺失代价的作用
- 5.3.4 一个cache的例子:内置FastMATH处理器
- 暂略
- 5.3.5 小结
- 访问和缺失小结
- 在缓存命中时, CPU 正常运行, 就像什么都没有发生一样
- 缓存丢失处理是与处理器控制单元和单独的控制器协作完成的
- 在缓存丢失时
- 停止 CPU 管道
- 从下一级内存层次结构中获取块
- 重新启动 CPU 管道
- 数据缓存丢失
- 完整的数据访问
- 访问和缺失小结
- 5.4 cache性能的评估和改进
- 第一种改进技术:
- 通过减少存储器中不同数据块征用cache中同一位置的概率来降低缺失率
- 第二种改进技术:
- 通过在存储器层次结构中额外增加一层来减少缺失代价
- 这里有几个公式,但我懒得看,P270
- 第一种改进技术:
- 5.4.1 通过更灵活地放置块来减少cache地缺失
- 上面提到,我们将一个块放入cache种,采用的是最简单的定位机制:一个块只能放到cache中一个明确的位置(即直接映射)
- 另一种方法是全相联:
- 全相联cache:cache的一种组织方式,块可以放到cache的任何位置
- 只适合块数较少的cache(因为需要比较器并行完成)
- 介于两者之间的方法是组相联:
- 组相联cache:cache的另一种组织方式,块可以放置到cache中的部分位置(至少两个)
- 组相联映射将直接映射和全相联映射结合起来:
- 一个块首先被直接映射到一个组,然后检索该组中所有的块判断是否匹配
- 直接映射中,一个存储块的位置是这样给出的:
- (块号) mod (cache中的块数)
- 而在组相联中
- (块号) mod (cache中的组数)
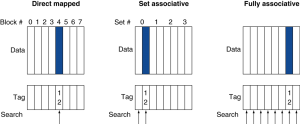
- 5.4.2 在cache中查找一个块
- 类似直接映射:标记 索引 块偏移
- 索引位:用来选择一个组
- 标记位:和选中的组中的块进行比较来选择块
- 块偏移:块中被请求的数据地址
- 但是因为顺序检索,所以导致命中时间太长
- 对比直接映射增多了3个比较器以及一个4选1的多路选择器
- 如果cache总容量不变,提高相联度就增加了每组中的块数,也就是并行查找比较的次数:
- 相联度每增加到两倍就会使
- 每组中的块数加倍而使组数减半
- 检索位减一位
- 标记位增一位
- 相联度增加会使得数据缺失率下降(因为一个索引中能存的标记多了)
- 相联度每增加到两倍就会使
- 任何存储器层次结构中选择直接映射、组相联还是全相联映射,需要在缺失代价和相联度之间进行权衡,既要考虑时间,也要考虑额外的硬件
- 类似直接映射:标记 索引 块偏移
- 5.4.3 替换块的选择
- 在组相联中同组替换块,全相邻中看作只有一组
- 最近最少使用(LRU算法):一种替换策略,总是替换很长时间没用使用的块
- 5.4.4 使用多级cache结构减少缺失代价
- 多级cache:存储系统由多级cache组成,而不仅仅只有主存和一个cache
- 这里有一道例题P277
- 5.4.5 通过分块进行软件优化
- 暂略
- 全局缺失率:在多级cache的所有级中都缺失的那部分访问
- 局部缺失率:在多级cache中,某一级cache的缺失率
- 5.4.6 小结
- 暂略
- 5.5 可信存储器层次
- P283懒得打字了